How to Scrape Google Search Results in 2026, Including News, Images, and Shopping Data
Learn how to scrape Google search results using Python and modern tools. Includes news, images, and shopping scraping with practical code and production strategies.
 Ahmed Ellaban
Ahmed Ellaban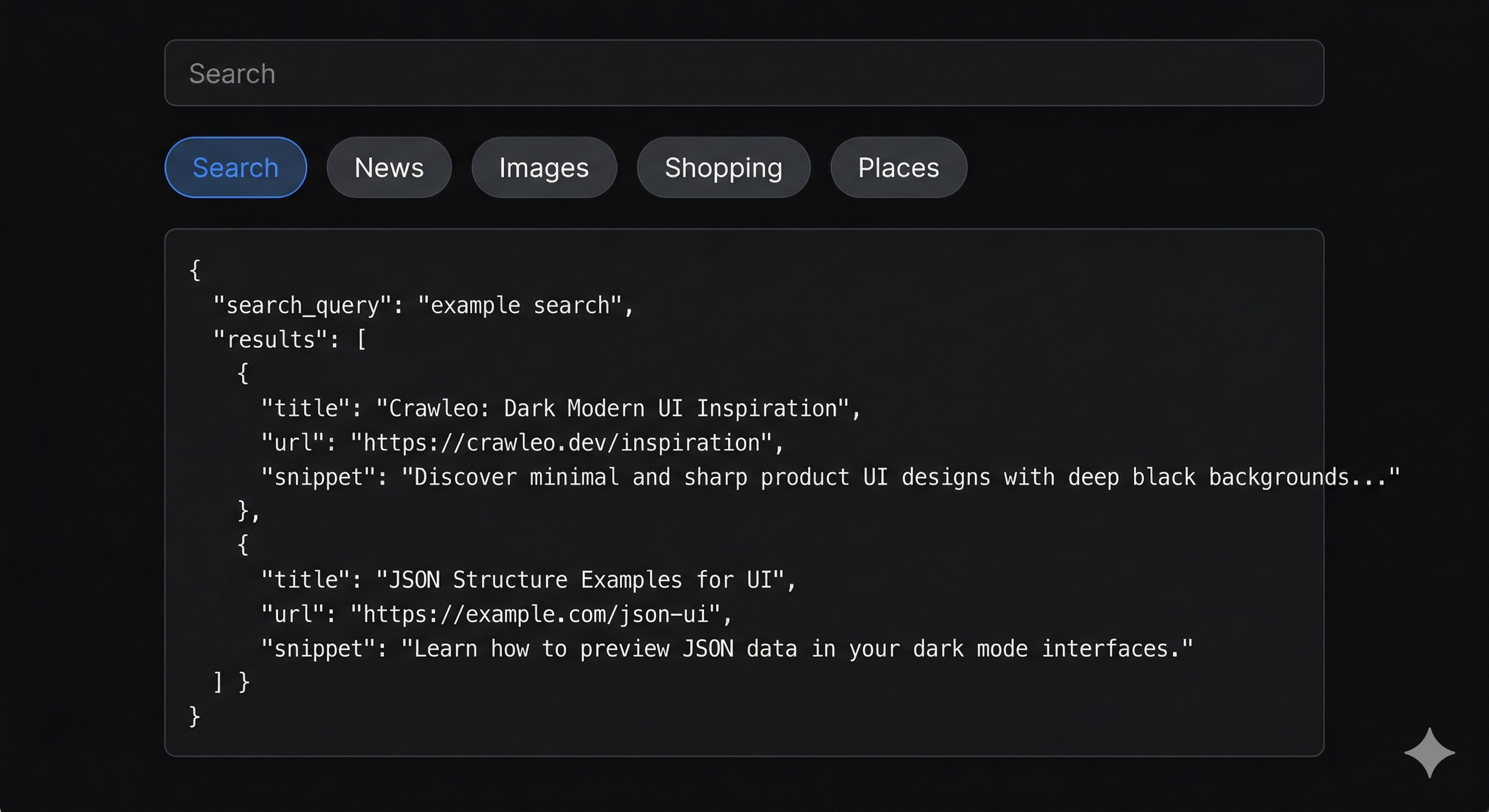
On this page
Introduction
Google SERP scraping is one of the most valuable data extraction tasks for SEO, AI systems, and market intelligence. However, it is also one of the hardest due to aggressive anti-bot systems, dynamic rendering, and constantly changing DOM structures.
In this guide, you will learn:
- How Google SERP works
- How to scrape search, news, images, and shopping
- Which libraries and tools to use
- How to scale scraping in production
What Is a Google SERP
A SERP (Search Engine Results Page) contains multiple data blocks:
- Organic results
- Featured snippets
- People Also Ask (PAA)
- News cards
- Image carousels
- Shopping listings
Each block has a different DOM structure, which makes scraping more complex than a typical website.
Method 1: Scraping Google with Python (Basic Approach)
Install Dependencies
pip install requests beautifulsoup4 lxml
Basic Request Example
import requests
from bs4 import BeautifulSoup
url = "https://www.google.com/search?q=python+scraping&hl=en&gl=us"
headers = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
Extract Organic Results
results = []
for g in soup.select("div.g"):
title = g.select_one("h3")
link = g.select_one("a")
if title and link:
results.append({
"title": title.text,
"link": link["href"]
})
Scraping Google News
Endpoint
https://www.google.com/search?q=keyword&tbm=nws
Extraction
for item in soup.select("div.dbsr"):
title = item.select_one("div.JheGif")
source = item.select_one("div.CEMjEf")
News scraping is useful for:
- Trend monitoring
- Brand tracking
- PR analysis
Scraping Google Images (Playwright)
Images require JavaScript rendering and scrolling.
Install
pip install playwright
playwright install
Example
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("https://www.google.com/search?q=cats&tbm=isch")
page.mouse.wheel(0, 5000)
images = page.eval_on_selector_all("img", "imgs => imgs.map(i => i.src)")
Challenges:
- Lazy loading
- Base64 images
- Hidden JSON data
Scraping Google Shopping
Endpoint
https://www.google.com/search?q=keyword&tbm=shop
Data Extraction
for item in soup.select(".sh-dgr__grid-result"):
title = item.select_one(".tAxDx")
price = item.select_one(".a8Pemb")
Shopping scraping is used for:
- Price tracking
- Competitor analysis
- E-commerce intelligence
Scaling Scraping in Production
A real system typically includes:
- Headless browsers (Playwright clusters)
- Proxy rotation (residential IPs)
- CAPTCHA solvers (2Captcha)
- Task queues (Kafka / RabbitMQ)
- Data storage (PostgreSQL / Elasticsearch)
Key Challenges
1. CAPTCHA and Bot Detection
Google detects automation via:
- TLS fingerprinting
- Behavioral signals
- IP reputation
2. IP Blocking
Solution:
- Residential proxies
- Geo-targeted IPs
3. DOM Changes
Selectors break frequently, requiring maintenance.
4. JavaScript Rendering
Many SERP elements require full browser execution.
Alternative Approach Using Crawleo
Instead of managing this full stack, Crawleo provides a single API that returns structured Google data.
It handles:
- Proxy rotation
- Anti-bot bypass
- SERP parsing
- Multi-vertical extraction
Supported types:
- search
- news
- images
- places
- shopping
Example:
GET https://api.crawleo.dev/google-search?q=python&type=news
Why This Matters
Manual scraping requires:
- Maintaining selectors
- Managing proxies
- Handling CAPTCHA
- Running browser clusters
Using an API removes this overhead and lets you focus on:
- Data usage
- Analysis
- Product development
If you are building:
- SEO tools
- AI agents
- RAG pipelines
- Market intelligence systems
You should benchmark your scraping stack against an API-based approach.
Explore:
Final Thoughts
Google scraping is no longer just parsing HTML. It is infrastructure, anti-bot engineering, and continuous maintenance.
The most scalable solution is often not scraping better, but abstracting scraping entirely.