Building Advanced AI Agents: How to Combine RAG with Real-Time Web Search
Learn how to bridge the gap between internal company knowledge and the live web. This guide explores a powerful pattern for building AI agents that can query private handbooks while simultaneously performing filtered real-time web searches to provide the most accurate, cited responses.
 Khaled Hawwas
Khaled Hawwas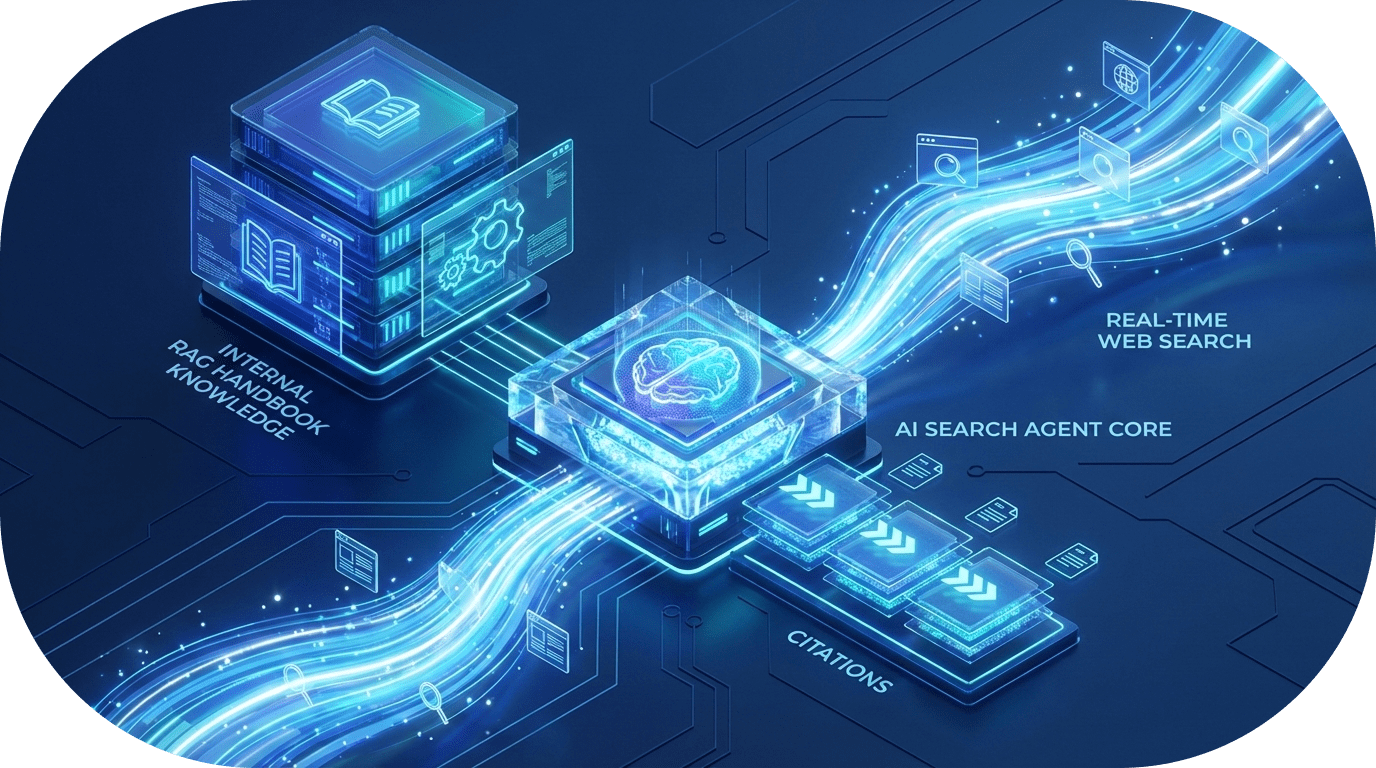
On this page
Building Hybrid AI Agents: Merging RAG with Real-Time Web Intelligence
A recurring bottleneck in AI development is the "Knowledge Cutoff." To build production-grade agents, developers must bridge the gap between static training data, internal proprietary knowledge, and the live web.
This hybrid architecture allows an agent to serve as a single source of truth for internal policies while using the web as a dynamic fallback—all within a controlled, "trust-but-verify" framework.
1. Transforming the Web into "AI-Ready" Data
The first challenge in any web-integrated pipeline is noise reduction. Raw HTML is filled with "token bloat"—scripts, ads, and navigation menus that confuse LLMs and drive up costs.
- The Solution: Tools like Docling (or similar markdown converters) are essential. They transform complex URLs or PDFs into clean, hierarchical Markdown.
- The Benefit: By converting a 100-page document (like the EU AI Act) into structured Markdown, you provide the LLM with a format that is easily chunked, summarized, and interpreted without the overhead of HTML tags.
2. Dynamic Search with "Agentic" Filtering
Searching the entire internet is often too broad for enterprise needs. Modern agents require Domain Filtering and Reasoning Loops to ensure the quality of their "External Brain."
Key Capabilities of a Search-Aware Tool:
- Domain Whitelisting: Restrict the agent to specific high-authority sources (e.g.,
*.gov,*.edu, or industry-specific documentation).- Reasoning-First Search: Using models like GPT-4.5 or specialized reasoning models allows the agent to evaluate the relevance of a search result before processing it.
- Verifiable Citations: By leveraging Pydantic models for structured output, the agent can return answers paired with direct URLs and text snippets, ensuring every claim is auditable.
3. The RAG Pattern: Treating Handbooks as Tools
In a sophisticated agentic workflow, Internal Knowledge (RAG) should not be a passive background process. Instead, treat your internal data—such as a company handbook or technical wiki—as a Function Call.
- Logic: The agent only triggers the "Search Internal Knowledge" tool when it detects a query related to specific corporate policies or private project data.
- Efficiency: This prevents "Context Contamination," where the model might accidentally prioritize a general web answer over a specific internal rule.
4. The Multi-Tool Orchestration Loop
The "Golden Path" for an AI assistant is a unified orchestration layer where multiple tools work in concert. A scalable architecture typically organizes these capabilities into a dedicated /tools directory.
The Decision-Making Process:
- Intent Analysis: Does the user want internal policy, a specific external URL, or a general market trend?
- Tool Selection: The agent selects the appropriate tool (Handbook RAG, Page Scraper, or Web Search).
- Cross-Reference & Synthesis: If necessary, the agent performs a "multi-hop" search—retrieving an internal rule and then checking the web for the latest external compliance update.
- Structured Response: The final output is synthesized into a clean reply, complete with citations.
Conclusion: The Next Step in AI Engineering
The transition from static chatbots to "search-aware" agents represents a major shift in how we build software. By combining Structured RAG with Real-Time Web Retrieval, you create tools that are grounded in your data but aware of the world.
For developers, the focus should remain on Type-Safe Tooling: Use Pydantic to enforce output schemas and modularize your tools so they can be easily swapped or upgraded as new scraping and search technologies emerge.
Pro-Tip: When building these agents, always implement a "Max Loop" limit on your reasoning steps. This prevents the agent from entering an infinite search loop if it encounters contradictory information on the web!

