General
What Are LLMs? A Plain-English Guide for Developers in 2026
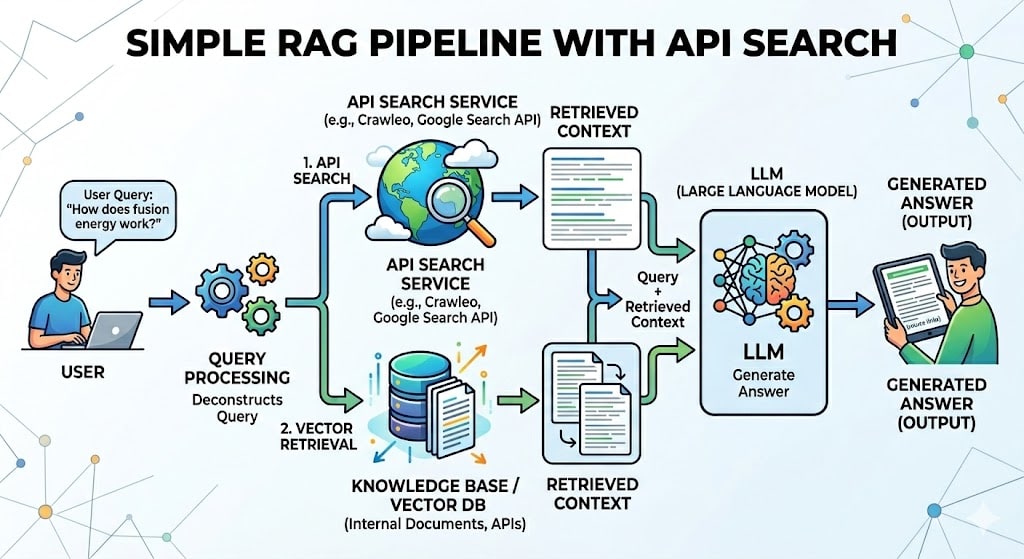
Large Language Models are no longer just research experiments — they're production infrastructure. Whether you're building a chatbot, a coding assistant, or a RAG pipeline, understanding how LLMs work and how to choose the right one is now a core developer skill.
29 Jun 20266 min read
225