The Best Local LLMs for 16GB RAM
Sixteen gigabytes of memory is the current sweet spot for developers exploring local large language models. With this capacity, you can efficiently run 7B to 14B parameter models using modern quantization techniques—delivering near-cloud performance while keeping your data on-premise. Whether you're...
 Khaled Hawwas
Khaled Hawwas
On this page
Sixteen gigabytes of memory is the current sweet spot for developers exploring local large language models. With this capacity, you can efficiently run 7B to 26B parameter models using modern quantization techniques—delivering near-cloud performance while keeping your data on-premise.
Whether you're building autonomous web crawling agents, coding assistants, or data analysis pipelines, optimizing for 16GB RAM (or VRAM) unlocks professional-grade AI without enterprise hardware costs.
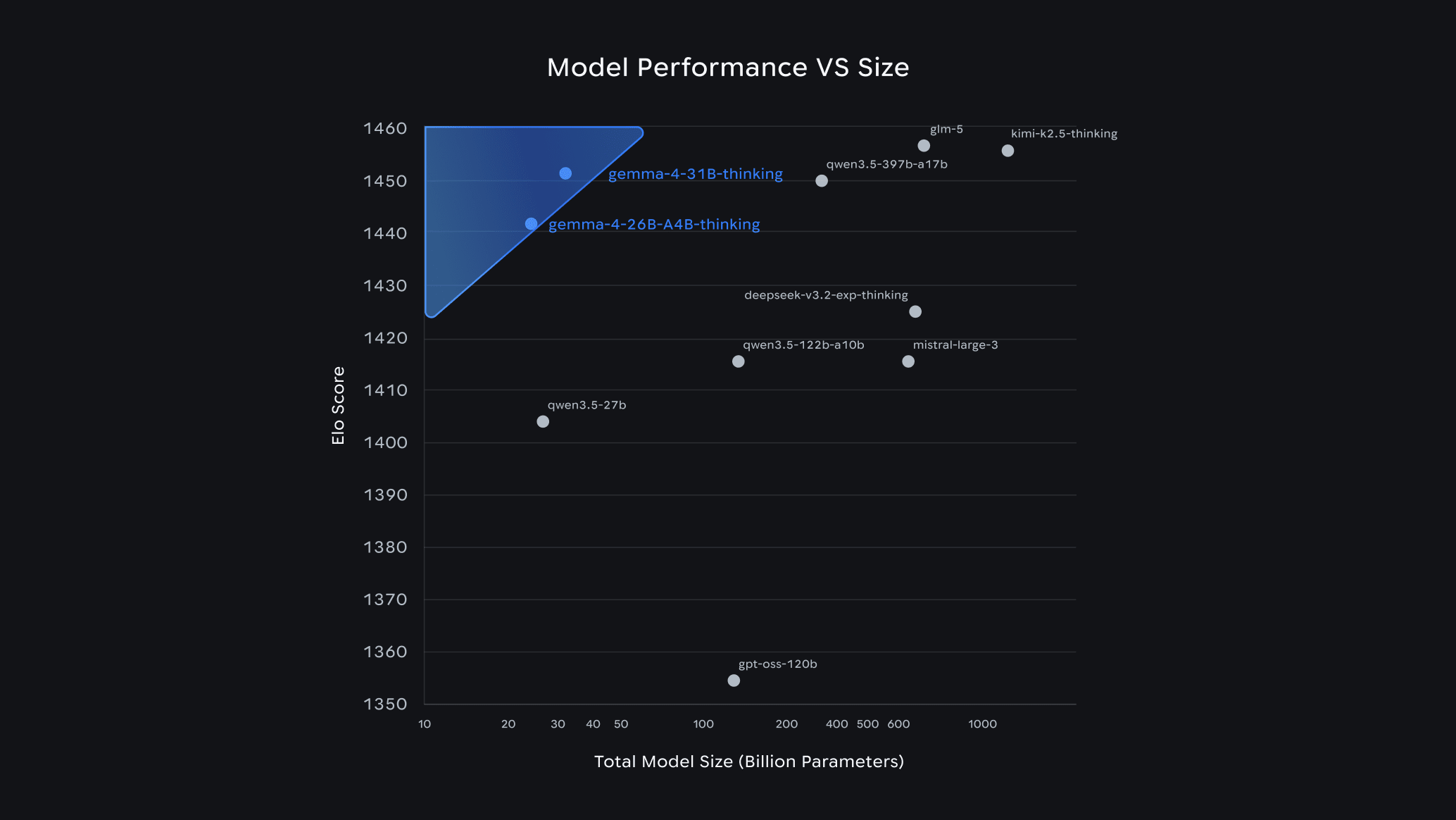
Best Overall: Gemma 4 26B MoE
For sheer capability within 16GB constraints, Gemma 4 26B MoE stands out as Google's most capable open model that can realistically run locally. At Q4_K_M quantization, it consumes approximately 16–18GB VRAM and achieves an Arena ELO of 1441 — landing at #6 among all open models worldwide. It delivers +8.7% on HumanEval (coding) and +14.2% on MMLU-Pro compared to Gemma 3, with −22% latency.
What makes it exceptional is its 256K context window and strong reasoning across extended inputs — Gemma 4's functional long-context recall went from 13.5% to 66.4% on multi-needle retrieval tests, meaning it can actually find information buried deep in long documents. This makes it ideal for:
- Multi-document research synthesis
- Complex code review and generation
- Structured data extraction from lengthy web crawls
⚠️ Note: On an RTX 4060 Ti 16GB, the 26B MoE runs at the absolute VRAM edge and may require 1–2GB of CPU RAM offload. Always use Q4_K_M quantization strictly.
How to Choose the Right Gemma 4 Variant
Gemma 4 comes in four sizes, each designed for a different hardware class. Here's the full breakdown — including what the numbers actually mean:
| Model | Architecture | Total Params | Active Params | Context | VRAM (Q4_K_M) | Best For |
|---|---|---|---|---|---|---|
| E2B | Dense (Edge) | 5.1B | 2.3B | 128K | ~5 GB | Mobile, browser, offline apps |
| E4B | Dense (Edge) | ~9B | ~4B | 128K | ~8 GB | Vision tasks, edge devices with multimodal needs |
| 26B MoE | Mixture-of-Experts | 25.2B | 3.8B active | 256K | ~16–18 GB | ✅ 16GB sweet spot — reasoning, coding, long context |
| 31B Dense | Dense | 30.7B | 30.7B | 256K | ~20 GB | Needs 24GB+ VRAM — best quality, fine-tuning |
What does "31B" mean?
The number refers to total parameters — the individual weights a model has learned during training. More parameters generally means more knowledge and reasoning capability. The 31B Dense model activates all 30.7 billion parameters on every single token, making it Google's highest-quality open model (ranked #3 globally on Arena AI). However, this means it needs ~20GB VRAM at 4-bit quantization — it won't fit on a 16GB card without heavy offloading.
What does "MoE" (Mixture of Experts) mean?
Instead of using all parameters every time, a MoE model has hundreds of small specialist networks ("experts") and a router that picks only the most relevant ones per token. The Gemma 4 26B MoE has 25.2B total parameters but only activates ~3.8B per token — so it runs at roughly the speed and memory cost of a 4B model, while producing quality close to the full 31B. It scores 1441 vs 1452 Arena ELO — a gap that's invisible in most real-world tasks.
So which one should you run on 16GB?
- 16GB VRAM GPU → Gemma 4 26B MoE at Q4_K_M (tight fit, but worth it for the quality leap)
- 12GB VRAM GPU → Gemma 4 E4B or Qwen3 14B (comfortable headroom, multimodal support)
- 8GB VRAM GPU → Llama 3.2 8B Q4_K_M (reliable, fast, leaves room for other processes)
- CPU-only 16GB RAM → Gemma 4 E4B or Llama 3.2 8B (keep under 8B active params for interactive latency)
📖 View all Gemma 4 variants and pull commands at the official Ollama library: ollama.com/library/gemma4
Top Alternatives by Use Case
Not every task requires maximum parameter count. Here are optimized picks for specific workflows:
| Model | Best For | Memory Usage | Speed | Key Advantage |
|---|---|---|---|---|
| Gemma 4 E4B | Vision, creative tasks, multimodal | ~8GB (Q4_K_M) | 20–40 t/s | Native multimodal (text + images), 128K context, audio input |
| Qwen3 14B | General purpose, efficiency | ~10–12GB | Variable | Strong reasoning with excellent VRAM efficiency |
| Mistral Small 3.1 (Q4) | Balanced performance | ~12GB | Variable | Robust all-rounder for consumer hardware |
| Qwen2.5-14B | Coding, software development | Fits in 16GB | Solid | Leading Python and Rust generation accuracy |
| Llama 3.2 8B (Q4_K_M) | Everyday automation | 4.8GB | 18 t/s | Best quality-to-size ratio, leaves RAM for other processes |
Specialized Recommendations
For Coding and Development
When building crawling spiders or API integrations, Qwen2.5-14B and Gemma 4 26B MoE dominate in syntax accuracy. They handle multi-file refactoring and complex debugging scenarios that trip up smaller 7B variants. Gemma 4 26B MoE shows a +8.7% improvement on HumanEval over its predecessor.
For Creative and Vision Tasks
Gemma 4 E4B offers native multimodal capabilities (text + images + audio) at only ~8GB VRAM — tasks typically requiring cloud vision APIs. At Q4_K_M, quantization quality loss is under 2.8% across benchmarks. It competes directly with larger vision models at a fraction of the memory cost.
For General Productivity
If you're running an LLM alongside IDE, browser, and database tools, Llama 3.2 8B quantized to Q4_K_M uses under 5GB VRAM. This leaves substantial headroom for your development environment while still delivering coherent completions for boilerplate generation and documentation.
Technical Optimization Tips
Quantization Strategy
Always prioritize Q4_K_M quantization for 16GB systems. This 4-bit method preserves model quality while halving memory requirements compared to FP16 — Gemma 4 loses less than 2.8% quality at this level. Avoid Q5 or Q6 quants on 16GB cards; they rarely justify the VRAM cost for marginal quality gains.
Context Window Management
Gemma 4 models support up to 128K–256K token context windows even at Q4_K_M on 16GB with careful management. For most development tasks — code completion, API documentation analysis, and structured extraction — 8K to 16K context suffices and keeps inference fast.
Hardware Acceleration
With an NVIDIA GPU (RTX 4060 Ti 16GB or RTX 4080), you can run these models fully CUDA-accelerated. On CPU-only systems with 16GB RAM, constrain yourself to 7B–8B parameters to maintain interactive latency below 20 tokens per second.
The Hardware Reality
Running local LLMs at 16GB represents the intersection of accessibility and capability. While cloud APIs offer larger models, local inference guarantees data privacy — critical when processing sensitive crawled data or proprietary codebases.
If your workflow involves processing high-volume web data, pairing an optimized local LLM with a robust crawling infrastructure ensures you can extract insights without transmitting raw data to third-party servers.
What will you primarily use your local LLM for? Coding assistance, data analysis, or content generation? Identifying your primary use case helps narrow whether you need Gemma 4 26B MoE's raw reasoning power or Gemma 4 E4B's efficient multimodal capabilities.