Best Web Scraping API for LLM Training Data and RAG Pipelines
Looking for a reliable web scraping API for LLM training data or RAG workflows? Discover how Crawleo delivers clean, real-time, privacy-first web data optimized for AI pipelines, without the complexity of traditional scraping infrastructure.
 Khaled Hawwas
Khaled Hawwas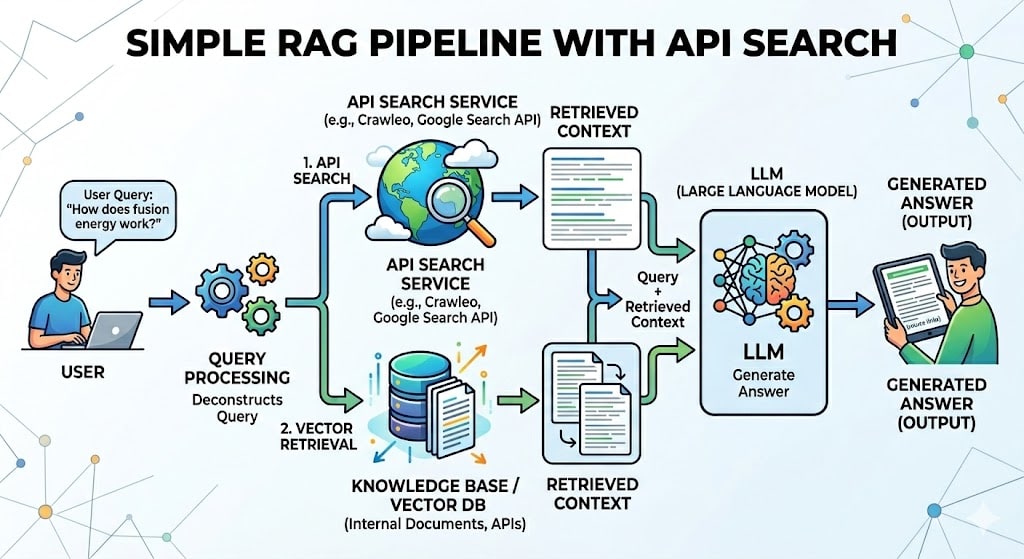
On this page
Best Web Scraping API for LLM Training Data and RAG Pipelines
Training or augmenting Large Language Models requires more than just web access. It requires clean structure, consistent formatting, and privacy-safe data pipelines.
If you are building:
- LLM pre-training datasets
- Domain-specific fine-tuning corpora
- Retrieval-Augmented Generation systems
- AI agents that need live knowledge
You need more than raw HTML. You need AI-ready web data.
Crawleo is built specifically for this purpose.
Why Web Data Quality Matters for LLMs
LLM performance is directly tied to data quality.
Raw HTML from websites typically includes:
- Navigation menus
- Ads and tracking scripts
- Cookie banners
- Repetitive boilerplate
- JavaScript-heavy rendering noise
This creates several problems:
- Wasted tokens during training
- Inconsistent document structure
- Lower signal-to-noise ratio
- Missing content from JavaScript-rendered pages
For RAG pipelines, the issue is even more critical. Poorly structured documents reduce embedding quality and retrieval precision.
Crawleo solves this by returning clean, structured, multi-format outputs optimized for AI systems.
How Crawleo Optimizes Web Data for AI Training
Crawleo is a privacy-first, real-time web search and crawling API designed for AI workflows.
1. Clean, Tokenizer-Friendly Output Formats
Crawleo supports multiple output types:
- Raw HTML
- AI-enhanced HTML, cleaned and script-free
- Plain text
- Markdown, optimized for RAG ingestion
Markdown is especially useful for LLM pipelines because it:
- Preserves headings and hierarchy
- Maintains lists and code blocks
- Removes unnecessary HTML artifacts
- Improves embedding quality
Example API call:
This returns structured markdown content ready for chunking and embedding.
2. Real-Time Web Access
Unlike static datasets or cached search results, Crawleo provides live web search and crawling.
This is critical for:
- Continually updated training corpora
- Knowledge-refresh pipelines
- AI agents that require current information
You can control:
querymax_pagescountsetLangccgeolocationdeviceauto_crawling
This flexibility allows precise dataset construction.
3. Built for RAG and AI Agents
Crawleo integrates natively with the Model Context Protocol at:
Available tools:
web.searchweb.crawl
This allows AI agents, IDE assistants, and autonomous workflows to fetch real-time web knowledge without custom scraping infrastructure.
For LangChain users, Crawleo provides:
CrawleoSearchCrawleoCrawler
Through the langchain-crawleo package, built on langchain-core.
This makes it straightforward to plug Crawleo directly into embedding and retrieval pipelines.
Consistent Formatting Across Millions of Pages
One of the biggest challenges in LLM dataset construction is inconsistency across sources.
Different websites use:
- Different HTML structures
- Different heading hierarchies
- Different content layouts
Crawleo normalizes this into consistent markdown output while preserving semantic structure.
The result:
- Reduced preprocessing effort
- Lower engineering overhead
- Cleaner training batches
- Improved model convergence
For ML teams, this translates into faster iteration cycles and more predictable dataset quality.
Privacy-First Data Handling for Enterprise AI
If you are building AI systems for enterprise clients, privacy matters.
Crawleo enforces:
- No persistent storage of search queries
- No storage of crawled page content
- No usage-content history
- No training of AI models on customer data
- No data selling
Only minimal metadata is processed for authentication, billing, and abuse prevention.
This makes Crawleo suitable for privacy-sensitive AI workflows and GDPR-aligned deployments.
When to Use Crawleo for LLM Workflows
Crawleo is particularly useful for:
Pre-Training Dataset Expansion
Gather large volumes of clean web documents across multiple domains.
Post-Training and Fine-Tuning
Build domain-specific corpora with consistent formatting and reduced noise.
RAG Systems
Fetch real-time content, extract markdown, chunk it, embed it, and serve it in retrieval pipelines.
AI Agents
Enable live web access inside agent frameworks using MCP or direct API integration.
Comparison Considerations When Choosing a Web Scraping API
When evaluating a web scraping API for AI use cases, consider:
- Does it handle JavaScript-rendered websites?
- Does it provide markdown or structured output?
- Is the data formatted consistently across domains?
- Is there zero data retention?
- Can it scale without managing infrastructure?
Crawleo is designed around these exact requirements.
Key Takeaways
- LLM performance depends heavily on clean, structured training data
- Raw HTML is inefficient and noisy for AI workflows
- Crawleo provides real-time search and crawling
- Supports markdown, text, raw HTML, and AI-enhanced HTML
- Designed for RAG, AI agents, and LLM training pipelines
- Enforces strict zero-retention privacy policies
- Scales serverlessly using Google Cloud Functions
If you are building AI products that rely on live web knowledge, choosing the right web scraping API directly impacts model quality, token efficiency, and operational cost.
Crawleo is built specifically for that layer of the AI stack.

